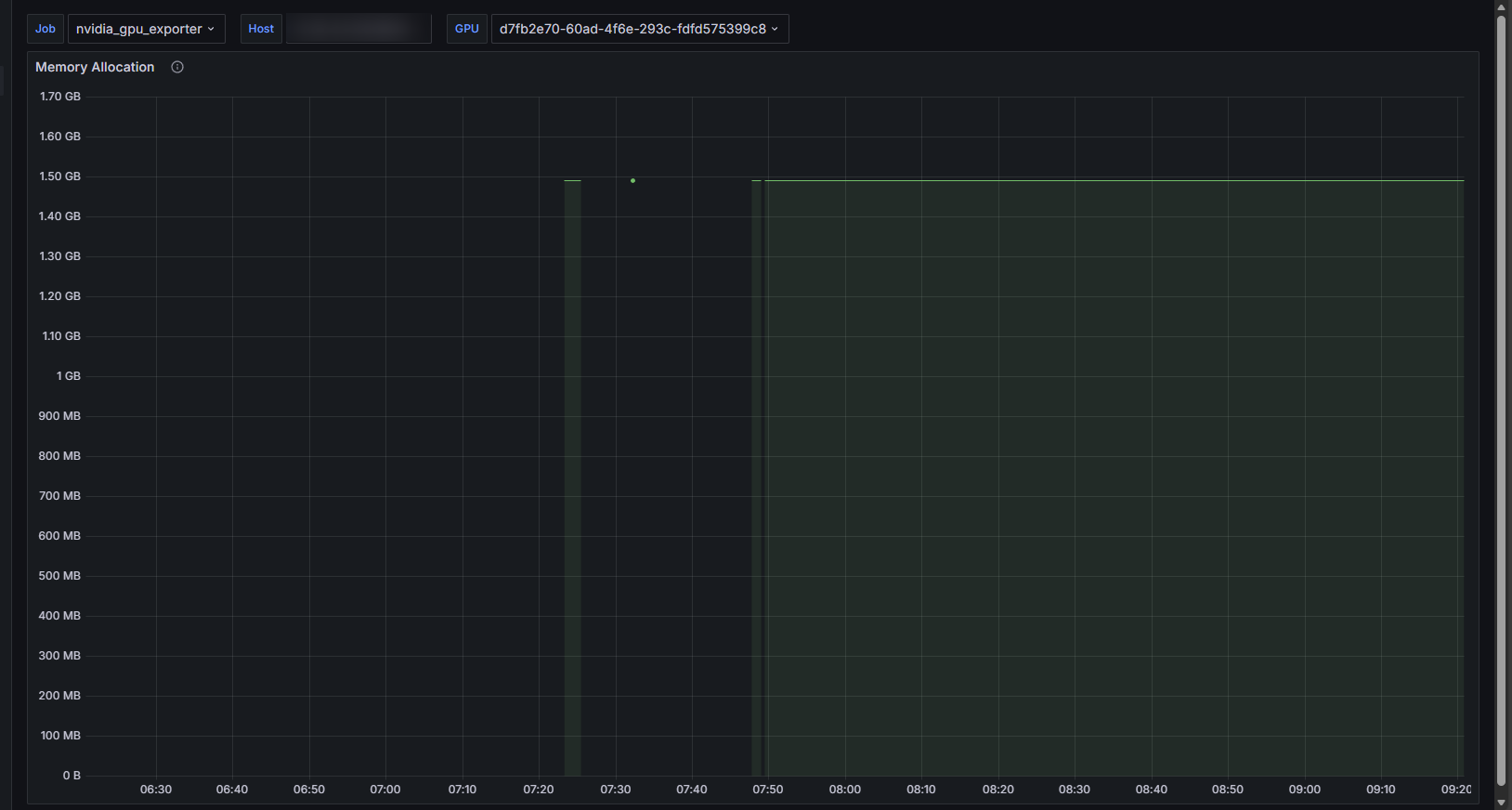
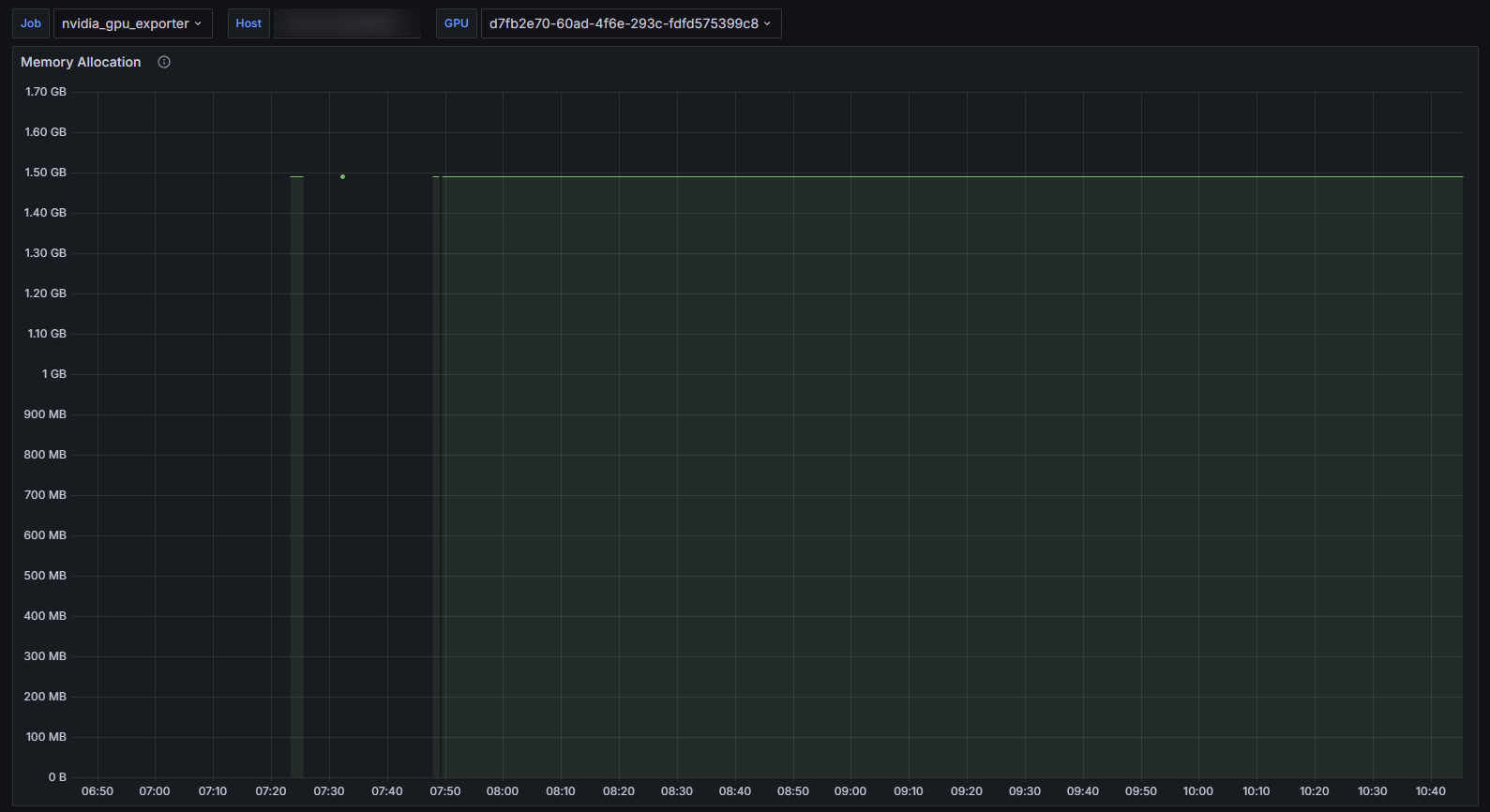
1
|
nvidia-smi --query-gpu=timestamp,driver_version,vgpu_driver_capability.heterogenous_multivGPU,count,name,serial,uuid,pci.bus_id,pci.domain,pci.bus,pci.device,pci.baseClass,pci.subClass,pci.device_id,pci.sub_device_id,vgpu_device_capability.fractional_multiVgpu,vgpu_device_capability.heterogeneous_timeSlice_profile,vgpu_device_capability.heterogeneous_timeSlice_sizes,vgpu_device_capability.homogeneous_placements,pcie.link.gen.current,pcie.link.gen.gpucurrent,pcie.link.gen.max,pcie.link.gen.gpumax,pcie.link.gen.hostmax,pcie.link.width.current,pcie.link.width.max,index,display_mode,display_active,persistence_mode,addressing_mode,accounting.mode,accounting.buffer_size,driver_model.current,driver_model.pending,vbios_version,inforom.img,inforom.oem,inforom.ecc,inforom.pwr,gpu_recovery_action,gom.current,gom.pending,fan.speed,pstate,clocks_event_reasons.supported,clocks_event_reasons.active,clocks_event_reasons.gpu_idle,clocks_event_reasons.applications_clocks_setting,clocks_event_reasons.sw_power_cap,clocks_event_reasons.hw_slowdown,clocks_event_reasons.hw_thermal_slowdown,clocks_event_reasons.hw_power_brake_slowdown,clocks_event_reasons.sw_thermal_slowdown,clocks_event_reasons.sync_boost,memory.total,memory.reserved,memory.used,memory.free,compute_mode,compute_cap,utilization.gpu,utilization.memory,utilization.encoder,utilization.decoder,utilization.jpeg,utilization.ofa,encoder.stats.sessionCount,encoder.stats.averageFps,encoder.stats.averageLatency,dramEncryption.mode.current,dramEncryption.mode.pending,ecc.mode.current,ecc.mode.pending,ecc.errors.corrected.volatile.device_memory,ecc.errors.corrected.volatile.dram,ecc.errors.corrected.volatile.register_file,ecc.errors.corrected.volatile.l1_cache,ecc.errors.corrected.volatile.l2_cache,ecc.errors.corrected.volatile.texture_memory,ecc.errors.corrected.volatile.cbu,ecc.errors.corrected.volatile.sram,ecc.errors.corrected.volatile.total,ecc.errors.corrected.aggregate.device_memory,ecc.errors.corrected.aggregate.dram,ecc.errors.corrected.aggregate.register_file,ecc.errors.corrected.aggregate.l1_cache,ecc.errors.corrected.aggregate.l2_cache,ecc.errors.corrected.aggregate.texture_memory,ecc.errors.corrected.aggregate.cbu,ecc.errors.corrected.aggregate.sram,ecc.errors.corrected.aggregate.total,ecc.errors.uncorrected.volatile.device_memory,ecc.errors.uncorrected.volatile.dram,ecc.errors.uncorrected.volatile.register_file,ecc.errors.uncorrected.volatile.l1_cache,ecc.errors.uncorrected.volatile.l2_cache,ecc.errors.uncorrected.volatile.texture_memory,ecc.errors.uncorrected.volatile.cbu,ecc.errors.uncorrected.volatile.sram,ecc.errors.uncorrected.volatile.total,ecc.errors.uncorrected.aggregate.device_memory,ecc.errors.uncorrected.aggregate.dram,ecc.errors.uncorrected.aggregate.register_file,ecc.errors.uncorrected.aggregate.l1_cache,ecc.errors.uncorrected.aggregate.l2_cache,ecc.errors.uncorrected.aggregate.texture_memory,ecc.errors.uncorrected.aggregate.cbu,ecc.errors.uncorrected.aggregate.sram,ecc.errors.uncorrected.aggregate.total,ecc.errors.uncorrected.volatile.sram.parity,ecc.errors.uncorrected.volatile.sram.secded,ecc.errors.uncorrected.aggregate.sram.parity,ecc.errors.uncorrected.aggregate.sram.secded,ecc.errors.uncorrected.aggregate.sram.thresholdExceeded,ecc.errors.uncorrected.aggregate.sram.l2,ecc.errors.uncorrected.aggregate.sram.sm,ecc.errors.uncorrected.aggregate.sram.mcu,ecc.errors.uncorrected.aggregate.sram.pcie,ecc.errors.uncorrected.aggregate.sram.other,retired_pages.single_bit_ecc.count,retired_pages.double_bit.count,retired_pages.pending,remapped_rows.correctable,remapped_rows.uncorrectable,remapped_rows.pending,remapped_rows.failure,remapped_rows.histogram.max,remapped_rows.histogram.high,remapped_rows.histogram.partial,remapped_rows.histogram.low,remapped_rows.histogram.none,temperature.gpu,temperature.gpu.tlimit,temperature.memory,power.management,power.draw,power.draw.average,power.draw.instant,power.limit,enforced.power.limit,power.default_limit,power.min_limit,power.max_limit,module.power.draw.average,module.power.draw.instant,module.power.limit,module.enforced.power.limit,module.power.default_limit,module.power.min_limit,module.power.max_limit,clocks.current.graphics,clocks.current.sm,clocks.current.memory,clocks.current.video,clocks.applications.graphics,clocks.applications.memory,clocks.default_applications.graphics,clocks.default_applications.memory,clocks.max.graphics,clocks.max.sm,clocks.max.memory,mig.mode.current,mig.mode.pending,gsp.mode.current,gsp.mode.default,c2c.mode,protected_memory.total,protected_memory.used,protected_memory.free,fabric.state,fabric.status,platform.chassis_serial_number,platform.slot_number,platform.tray_index,platform.host_id,platform.peer_type,platform.module_id,platform.gpu_fabric_guid --format=csv
|